
LLaDA2.0:拡散モデルで実現する次世代大規模言語モデル

LLaDA2.0:拡散モデルで実現する次世代大規模言語モデル
導入:言語モデルの新たなパラダイム
大規模言語モデル(LLM)といえば、GPTやLLaMAに代表される自己回帰型モデル(ARM)が主流でした。しかし、inclusionAI(Ant Group)が発表したLLaDA2.0は、拡散モデル(Diffusion Model)という全く異なるアプローチで言語モデリングに挑戦し、従来の常識を覆す成果を上げています。
LLaDA2.0は、画像生成で成功を収めた拡散モデルの原理を言語処理に適用し、マスキングと段階的な生成プロセスを通じて高品質なテキストを生成します。特に注目すべきは、Mixture-of-Experts(MoE)アーキテクチャとの組み合わせにより、計算効率と性能を両立している点です。
LLaDA2.0の革新的アーキテクチャ
拡散言語モデルの仕組み
LLaDAシリーズは、従来の左から右へ順次トークンを生成する自己回帰方式ではなく、マスキングと復元のプロセスを採用しています。

このアプローチには以下のような利点があります:
- 双方向コンテキストの活用:自己回帰型が左側のトークンしか参照できないのに対し、拡散モデルは文脈全体を考慮可能
- Reversal Curseの解決:「A→B」の関係を学習すれば「B→A」も理解できる(GPT-4oを上回る性能)
- 確率的推論:尤度下界の最適化により、より原理的な生成アプローチを実現
Mixture-of-Experts(MoE)による効率化
LLaDA2.0-miniは、16B総パラメータで推論時には1.4Bのみを活性化するMoEアーキテクチャを採用しています。
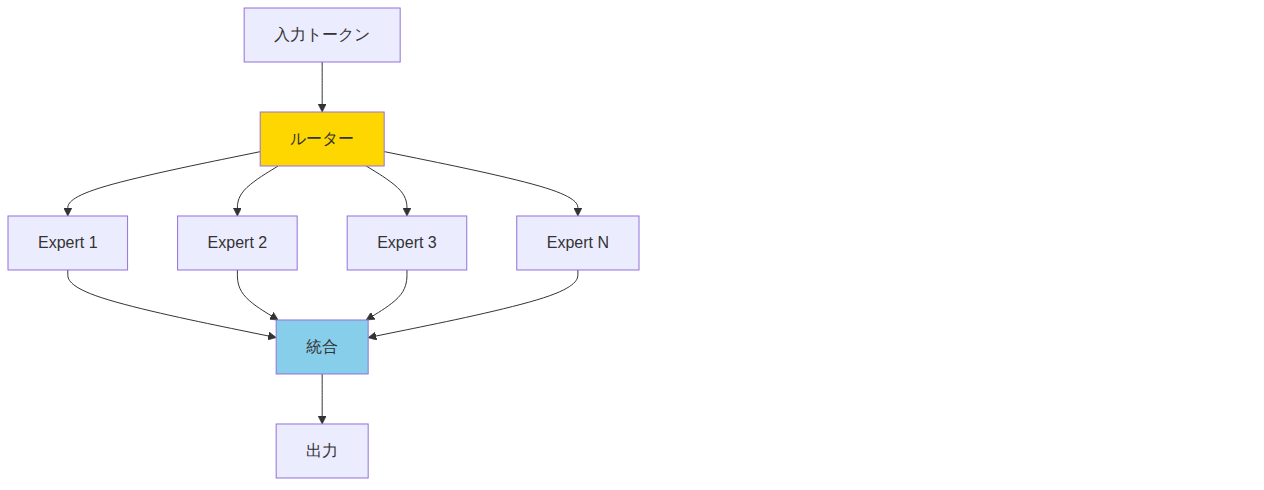
この設計により:
- 計算コストを大幅削減:推論時のアクティブパラメータは約1/10
- スケーラビリティ:20兆トークンでの継続事前学習を実現
- 専門性の向上:各Expertが特定の知識領域に特化
ベンチマーク性能:実力を数字で検証
LLaDA2.0-mini-previewは、様々なタスクで優れた性能を発揮します:
知識ベンチマーク
- MMLU: 72.49(多分野理解)
- CMMLU: 67.53(中国語理解)
- C-EVAL: 66.54(総合評価)
コーディング性能
- HumanEval: 80.49(コード生成)
- MBPP: 77.75(Pythonプログラミング)
- CruxEval-O: 61.88(コード理解)
特筆すべきは、コード生成と複雑な推論タスクでの強さです。同規模の密モデルを上回り、ツール呼び出し(BFCL_Live: 74.11)やエージェントタスクでも高い性能を示しています。
数学的推論
- GSM8K: 89.01(小学校レベルの数学)
- MATH: 73.50(高度な数学問題)
これらの結果は、拡散モデルが複雑な論理的推論にも対応できることを証明しています。
実装と活用方法
モデルの読み込み
LLaDA2.0は、Hugging Face Transformersで簡単に利用できます:
from transformers import AutoModel, AutoTokenizer
import torch
# モデルとトークナイザーの読み込み
tokenizer = AutoTokenizer.from_pretrained(
'inclusionAI/LLaDA2.0-mini-preview',
trust_remote_code=True
)
model = AutoModel.from_pretrained(
'inclusionAI/LLaDA2.0-mini-preview',
trust_remote_code=True,
torch_dtype=torch.bfloat16
)
# 推論の実行
text = "Write a Python function to calculate fibonacci numbers:"
response = model.generate(text)
print(response)
モデルバリアント
LLaDA2.0には複数のバリアントが用意されています:
| モデル | パラメータ | 特徴 |
|---|---|---|
| LLaDA2.0-mini-preview | 16B (1.4B active) | 効率重視、コード生成に強い |
| LLaDA2.0-flash-preview | 103B | 大規模タスク向け高性能版 |
実践的なベストプラクティス
1. タスクに応じたモデル選択
- コード生成・数学問題: mini-previewで十分な性能
- 複雑な推論・長文生成: flash-previewを推奨
2. 推論パラメータの調整
拡散モデル特有のパラメータ: - Diffusion steps: 生成品質とスピードのトレードオフ - Temperature: 創造性の制御(自己回帰型と同様)
3. ツール呼び出しの活用
LLaDA2.0はFunction Callingに優れており、外部ツールとの統合が効果的です。
技術的な展望と今後のロードマップ
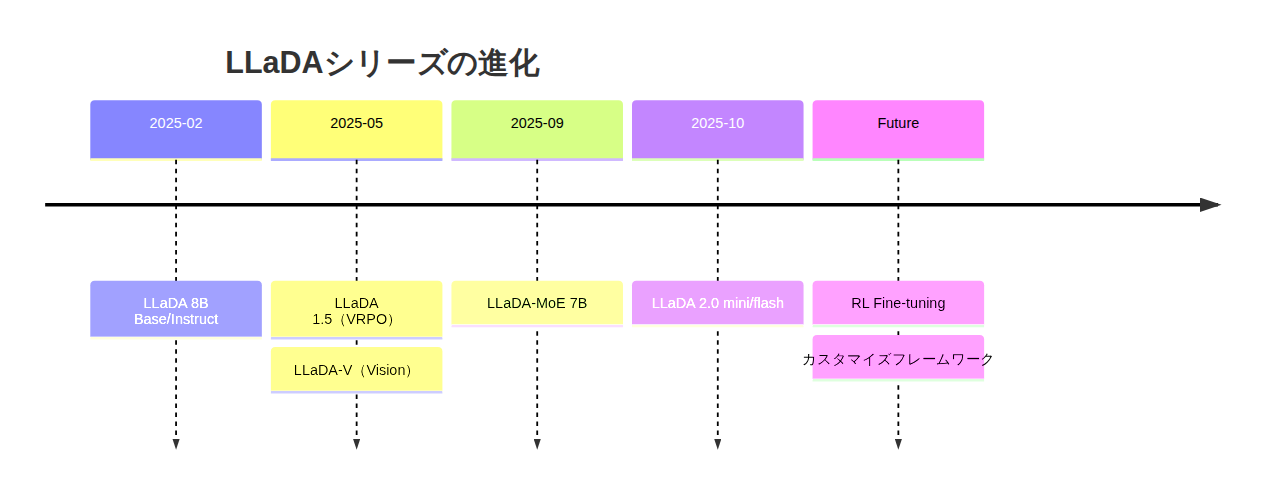
強化学習による性能向上
inclusionAIは、Reinforcement Learning(RL)によるファインチューニングを計画しており、さらなる推論能力の向上が期待されます。
LLaDA 1.5とLLaDA-V
- LLaDA 1.5: VRPO(分散削減を伴う選好最適化)による改良版
- LLaDA-V: 視覚言語モデル版、マルチモーダル対応
オープンソースエコシステム
inclusionAIは以下を公開予定: - 最適化された推論フレームワーク - ポストトレーニングフレームワーク - 詳細なチュートリアル
まとめ:拡散モデルが拓く新しい可能性
LLaDA2.0は、大規模言語モデルにおいて拡散モデルが自己回帰型に匹敵する性能を発揮できることを実証しました。特にMoEアーキテクチャとの組み合わせにより、効率性と性能を高次元で両立しています。
主要な利点
- 計算効率: 推論時のアクティブパラメータが少ない
- 双方向理解: コンテキスト全体を考慮した生成
- 専門タスク: コード生成と数学的推論に強い
- 拡張性: オープンソースで自由にカスタマイズ可能
自己回帰型が唯一の解ではないという事実は、AI研究に新たな地平を開きます。LLaDA2.0は、その先駆けとして今後のLLM開発に大きな影響を与えるでしょう。開発者や研究者にとって、この革新的なアプローチを試す絶好の機会です。